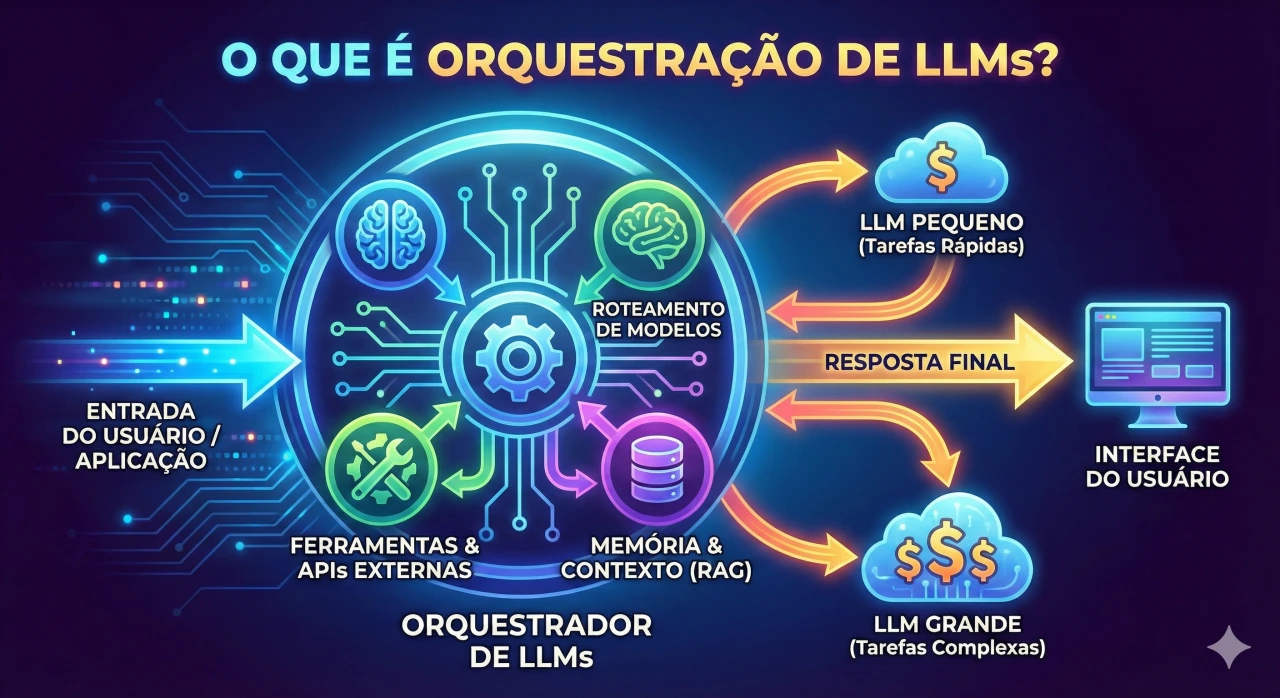
O que é orquestração de LLMs?
É a gestão e otimização de modelos de linguagem em aplicações reais.
Quais são as vantagens de orquestrar LLMs?
Redução de custo, confiabilidade, escalabilidade, segurança e evolução contínua.
Quais ferramentas são usadas para orquestração de LLMs?
Algumas ferramentas incluem n8n, LangChain, LlamaIndex e Orq.ai.
Como o n8n auxilia na orquestração de LLMs?
O n8n permite automação low-code com integrações e nodes específicos para LLMs.
Orquestração de LLMs é o conjunto de técnicas, frameworks e infraestruturas usados para gerenciar, coordenar e otimizar o uso de modelos de linguagem (LLMs) dentro de aplicações reais, conectando-os a dados, APIs, fluxos de trabalho e monitoria.
Esse conceito é muito usado na criação de Agentes de IA complexos, onde é preciso usar muitas LLMs diferentes, APIs de serviços, Memória RAG e outras funções. Lembrando que aqui na Naweb, somos especialistas na criação desse tipo de agentes, entre em contato e escale sua empresa.
Em vez de apenas chamar um endpoint de “chat completion”, a orquestração cria uma camada de integração que cuida de:
- Encadear prompts e chamadas múltiplas de LLM (prompt chaining, agentes, ferramentas).
- Conectar o LLM com bancos de dados, vetores, APIs de terceiros e sistemas internos.
- Manter contexto e memória de conversas (curto e longo prazo).
- Fazer roteamento inteligente entre diferentes modelos (pequenos e rápidos vs grandes e caros).
- Monitorar qualidade, logging e observabilidade da aplicação de IA.
Em termos de arquitetura, a orquestração funciona como um “backbone” que fala com:
- Provedores de LLM (OpenAI, Anthropic, Gemini, Groq, modelos self-hosted, etc.).
- Camadas de contexto (vector DBs, caches, data lakes, APIs internas).
- Camadas de aplicação (front-end web, WhatsApp, Slack, sistemas legados).
2. Por que orquestrar LLMs?
Algumas razões técnicas pelas quais a orquestração é essencial em produção:
- Redução de custo e latência: usar modelos menores para tarefas simples (ex.: sumarização) e maiores apenas quando necessário.
- Confiabilidade e controle: centralizar prompts, logs, métricas e políticas de uso.
- Escalabilidade: suportar múltiplos fluxos simultâneos, filas, retries, rate limits, etc.
- Segurança e compliance: controlar quais dados vão para qual LLM, mascarar PII, auditar acessos.
- Evolução contínua: trocar modelos, alterar prompts e fluxos sem quebrar toda a aplicação.
Um exemplo simples: um assistente de WhatsApp para uma marmoraria que:
- Recebe mensagens via webhook.
- Usa um LLM menor para classificar intenção (orçamento, status, reclamação).
- Consulta um banco ou API de ERP.
- Usa um LLM maior para redigir respostas complexas ou negociar.
- Loga tudo em um sistema de observabilidade específico para LLMs.
Tudo isso é orquestração – amarração dos componentes em um fluxo consistente e robusto.
3. Arquiteturas e padrões de orquestração de LLM
3.1 Componentes típicos
Uma arquitetura de orquestração de LLM costuma incluir:
- Orchestrator / Framework: camada que define chains, agentes, fluxos e integração (ex.: LangChain, LlamaIndex, n8n).
- Model Router: decide qual modelo usar para cada tarefa (por custo, latência, capacidade).
- Memory Store: banco ou serviço para guardar histórico e conhecimento (vetor, Redis, Postgres, etc.).
- Tools / Functions: funções externas (chamadas HTTP, DB, ferramentas de cálculo) que o LLM pode acionar.
- Monitoria & Observabilidade: logging, tracing, métricas, testes de regressão de prompts.
3.2 Padrões comuns
Alguns padrões muito usados:
- RAG (Retrieval-Augmented Generation): recuperar contexto relevante em um vetor DB e injetar no prompt.
- Agentic workflows: agentes que decidem quais ferramentas chamar, em qual ordem, até alcançar um objetivo.
- Multi-LLM orchestration: dividir pipeline entre modelos diferentes (classificação, extração, geração).
- Guardrails: checagens de segurança/qualidade antes de devolver a resposta (reclassificação, filtros, validação de formato).
4. Ferramentas de orquestração: panorama geral
4.1 Visão geral (tabela)
Tabela com algumas das principais ferramentas de orquestração ou frameworks ao redor de LLMs:
5. n8n como plataforma de orquestração de LLM
n8n é uma plataforma de automação low-code, open source, focada em fluxos de trabalho com centenas de integrações, que hoje oferece nós específicos para LangChain e IA, o que o transforma em uma peça forte para orquestração de LLMs.
Você pode rodar n8n self-hosted (Docker, Kubernetes, etc.) ou usar o cloud, permitindo integrar IA com WhatsApp, CRMs, bancos de dados, e qualquer API HTTP.
5.1 n8n + LangChain
A equipe do n8n implementou uma coleção de nodes que encapsulam funcionalidades do LangChain, permitindo:
- Escolher o LLM (OpenAI, Anthropic, etc.) como backend.
- Configurar agentes, memória, ferramentas e prompt templates via interface.
- Interligar esses nodes de LangChain com qualquer outro node do n8n (HTTP Request, Postgres, Webhook, etc.).
Isso viabiliza arquiteturas onde:
- O webhook do WhatsApp dispara um workflow.
- Um node de LangChain faz RAG com um vector DB.
- Outro node escreve logs em um banco.
- Um node HTTP chama webhooks externos.
5.2 Exemplo de workflow orquestrado no n8n
Um fluxo típico para atendimento automático:
- Node Webhook: recebe mensagem do WhatsApp Business API.
- Node Function (JS): normaliza payload, extrai texto, ID do usuário.
- Node LangChain LLM: usa modelo pequeno para classificar intenção.
- Branch: com base na intenção, segue para:
- Node HTTP (consultar ERP / CRM).
- Node Database (Postgres / Supabase).
- Node LangChain Agent: compõe resposta usando contexto retornado.
- Node Webhook Reply / HTTP: envia a resposta de volta via API do provedor de WhatsApp.
Esse fluxo é puro orquestrador: cada node é uma parte do pipeline, o LLM é apenas mais um componente bem acoplado.
5.3 Vantagens do n8n para LLM orchestration
- Visual: ótima visão de pipeline, útil para debugging e para compartilhar com time não-dev.
- Híbrido: combina IA, bancos de dados, integrações SaaS e lógica custom via Function Node.
- Extensível: dá para chamar qualquer API de LLM, mesmo não suportada nativamente, via HTTP node.
- Self-hosted: rodar perto dos seus dados, em infra própria, com menos vazamento de contexto.
6. Outras ferramentas de orquestração
6.1 Open source / foco em código
- LangChain: framework Python/TypeScript orientado a “chains” e “agents”, com integrações para dezenas de LLMs, vector DBs, ferramentas e sistemas.
- LlamaIndex: foca em RAG, construção de índices, conectores de dados (files, DB, APIs) e consultas otimizadas a partir de LLMs.
- Deepchecks para LLM: não é um orquestrador de fluxo em si, mas uma camada essencial de QA e monitoria sobre pipelines orquestrados.
6.2 Plataformas pagas / SaaS
- Orq.ai: plataforma que oferece UI para montar pipelines, roteamento de modelos, AB testing e observabilidade de orquestração multi-LLM.
- Serviços comerciais de LangChain (LangSmith): para logging, tracing e testes de prompts e chains em produção.
7. Técnicas usando código puro (sem plataforma)
Você, como dev, pode orquestrar LLMs usando apenas código (Python, Node, etc.) + SDKs/APIs. A vantagem é controle total, custo direto e flexibilidade.
7.1 Estrutura típica com código
Em código puro, você cria manualmente:
- Camada de provider: wrappers para cada LLM (OpenAI, Gemini, etc.).
- Camada de orchestration: funções que definem chains (ex.:
classificar_intencao(),gerar_resposta()). - Camada de dados: funções para RAG (busca em vetor DB, SQL, Redis).
- Camada de infra: filas, rate limits, retries, logs e métricas.
Pseudocódigo de um mini-orquestrador em estilo code-first:
def classify_intent(message):
prompt = f"Classifique a intenção da mensagem: {message}"
return call_llm_small(prompt)
def fetch_context(intent, user_id):
if intent == "orcamento":
return query_postgres("SELECT ... WHERE user_id = %s", [user_id])
if intent == "status_pedido":
return call_internal_api("/orders/status", {"user": user_id})
return ""
def generate_reply(message, intent, context):
prompt = f"""
Usuário: {message}
Intenção: {intent}
Contexto: {context}
Gere uma resposta educada e objetiva.
"""
return call_llm_large(prompt)
def orchestrate(message, user_id):
intent = classify_intent(message)
context = fetch_context(intent, user_id)
reply = generate_reply(message, intent, context)
log_interaction(user_id, message, intent, reply)
return reply
Esse padrão é exatamente o que frameworks como LangChain abstraem para você, porém você pode escrever tudo na mão conforme sua necessidade.
7.2 Multi-LLM e roteamento manual
Você também pode implementar roteamento manual com base em:
- Tamanho do input (tokens).
- SLA de resposta.
- Importância / criticidade da tarefa.
Exemplo: usar modelo X rápido para classificação e modelo Y para geração final, como descrito em estratégias de orquestração multi-modelo.
8. Vibe coding aplicado à orquestração
8.1 O que é vibe coding
Vibe coding é uma abordagem de desenvolvimento em que o dev descreve o que quer em linguagem natural para um LLM, que gera o código automaticamente, enquanto o dev foca em testar e ajustar via prompts, sem se apegar ao código em si.
A ideia é deixar o LLM gerar grande parte da arquitetura, boilerplate e integrações, e você validar pelo comportamento (testes, logs), não por revisão linha a linha.
8.2 Como usar vibe coding para orquestração
Você pode combinar vibe coding com orquestração de LLMs de algumas formas:
- Gerar scaffolding de pipelines em código: pedir para o LLM criar uma API em FastAPI/Express que implemente RAG e multi-LLM, e depois ir iterando.
- Criar nodes/custom integrations para n8n: pedir o código de um node custom para falar com um LLM self-hosted via HTTP, testando no runtime do n8n.
- Projetar agentes complexos: descrever o objetivo (ex.: “agente financeiro que orquestra múltiplos LLMs e APIs bancárias”) e deixar o LLM montar a estrutura de agents, memory e tools, que você depois conecta em LangChain ou n8n.
Pesquisas recentes destacam que vibe coding funciona melhor quando há:
- Contexto bem estruturado (descrição clara da stack, dos serviços e das constraints).
- Ciclo de feedback rápido (testes automatizados, logs claros).
- Modelos de colaboração humano-IA bem definidos (conversas iterativas, planejamento explícito).
9. Comparando abordagens: low-code vs código puro vs vibe coding
Tabela comparativa de abordagens
Na prática, muitos times combinam:
- n8n para orquestrar integrações externas e fluxo.
- LangChain/LlamaIndex para RAG e agentes complexos.
- Vibe coding para gerar rapidamente módulos ou serviços que depois são refinados manualmente.
10. Boas práticas para orquestração de LLM em produção
Algumas diretrizes técnicas importantes, sintetizadas de discussões sobre melhores práticas de orquestração:
- Separar orquestração da lógica de negócio: manter uma camada clara onde estão chains, prompts e chamadas de LLM, separada do domínio.
- Centralizar prompts: versionar templates de prompts, ter testes de regressão para mudanças críticas.
- Monitorar tudo: logar prompts, respostas, erros, tempo de resposta e custos.
- Usar RAG em vez de fine-tuning quando possível: principalmente quando os dados mudam com frequência.
- Implementar guardrails: validação de formato, filtros de conteúdo, checagens de segurança.
- Escolher bem o mix de ferramentas: usar n8n (ou similar) para automação e integrações, um framework code-first para lógica de IA sofisticada e vibe coding para acelerar desenvolvimento – mas sempre com testes automatizados.

